A regular expression is a way of describing a sequence of characters. Regular expressions are a stunningly powerful computational device. However, describing the languages used to define regular expressions is well beyond the scope of this Primer. Instead, we’ll focus on how to use the C++ regular-expression library (RE library), which is part of the new library. The RE library, which is defined in the regex header, involves several components, listed in Table 17.4.
Table 17.4. Regular Expression Library Components

If you are not already familiar with using regular expressions, you might want to skim this section to get an idea of the kinds of things regular expressions can do.
The regex class represents a regular expression. Aside from initialization and assignment, regex has few operations. The operations on regex are listed in Table 17.6 (p. 731).
The functions regex_match and regex_search determine whether a given character sequence matches a given regex. The regex_match function returns true if the entire input sequence matches the expression; regex_search returns true if there is a substring in the input sequence that matches. There is also a regex_replace function that we’ll describe in § 17.3.4 (p. 741).
The arguments to the regex functions are described in Table 17.5 (overleaf). These functions return a bool and are overloaded: One version takes an additional argument of type smatch. If present, these functions store additional information about a successful match in the given smatch object.
Table 17.5. Arguments to regex_search and regex_match

As a fairly simple example, we’ll look for words that violate a well-known spelling rule of thumb, “i before e except after c”:
// find the characters ei that follow a character other than c
string pattern("[^c]ei");
// we want the whole word in which our pattern appears
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern); // construct a regex to find pattern
smatch results; // define an object to hold the results of a search
// define a string that has text that does and doesn't match pattern
string test_str = "receipt freind theif receive";
// use r to find a match to pattern in test_str
if (regex_search(test_str, results, r)) // if there is a match
cout << results.str() << endl; // print the matching word
We start by defining a string to hold the regular expression we want to find. The regular expression [^c] says we want any character that is not a 'c', and [^c]ei says we want any such letter that is followed by the letters ei. This pattern describes strings containing exactly three characters. We want the entire word that contains this pattern. To match the word, we need a regular expression that will match the letters that come before and after our three-letter pattern.
That regular expression consists of zero or more letters followed by our original three-letter pattern followed by zero or more additional characters. By default, the regular-expression language used by regex objects is ECMAScript. In ECMAScript, the pattern [[:alpha:]] matches any alphabetic character, and the symbols + and * signify that we want “one or more” or “zero or more” matches, respectively. Thus, [[:alpha:]]* will match zero or more characters.
Having stored our regular expression in pattern, we use it to initialize a regex object named r. We next define a string that we’ll use to test our regular expression. We initialize test_str with words that match our pattern (e.g., “freind” and “theif”) and words (e.g., “receipt” and “receive”) that don’t. We also define an smatch object named results, which we will pass to regex_search. If a match is found, results will hold the details about where the match occurred.
Next we call regex_search. If regex_search finds a match, it returns true. We use the str member of results to print the part of test_str that matched our pattern. The regex_search function stops looking as soon as it finds a matching substring in the input sequence. Thus, the output will be
freind
§ 17.3.2 (p. 734) will show how to find all the matches in the input.
regex ObjectWhen we define a regex or call assign on a regex to give it a new value, we can specify one or more flags that affect how the regex operates. These flags control the processing done by that object. The last six flags listed in Table 17.6 indicate the language in which the regular expression is written. Exactly one of the flags that specify a language must be set. By default, the ECMAScript flag is set, which causes the regex to use the ECMA-262 specification, which is the regular expression language that many Web browsers use.
Table 17.6. regex (and wregex) Operations
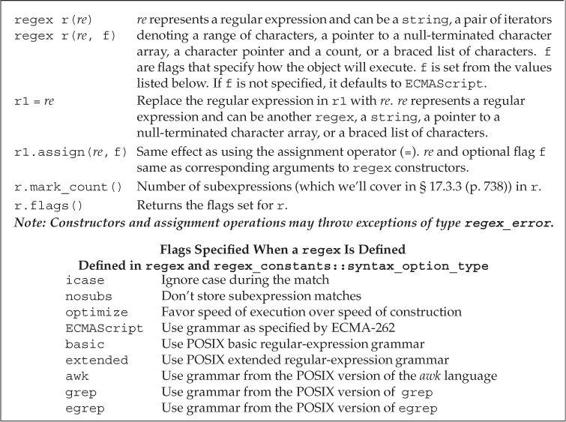
The other three flags let us specify language-independent aspects of the regular-expression processing. For example, we can indicate that we want the regular expression to be matched in a case-independent manner.
As one example, we can use the icase flag to find file names that have a particular file extension. Most operating systems recognize extensions in a case-independent manner—we can store a C++ program in a file that ends in .cc, or .Cc, or .cC, or .CC. We’ll write a regular expression to recognize any of these along with other common file extensions as follows:
// one or more alphanumeric characters followed by a '.' followed by "cpp" or "cxx" or "cc"
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);
smatch results;
string filename;
while (cin >> filename)
if (regex_search(filename, results, r))
cout << results.str() << endl; // print the current match
This expression will match a string of one or more letters or digits followed by a period and followed by one of three file extensions. The regular expression will match the file extensions regardless of case.
Just as there are special characters in C++ (§ 2.1.3, p. 39), regular-expression languages typically also have special characters. For example, the dot (.) character usually matches any character. As we do in C++, we can escape the special nature of a character by preceding it with a backslash. Because the backslash is also a special character in C++, we must use a second backslash inside a string literal to indicate to C++ that we want a backslash. Hence, we must write \\. to represent a regular expression that will match a period.
We can think of a regular expression as itself a “program” in a simple programming language. That language is not interpreted by the C++ compiler. Instead, a regular expression is “compiled” at run time when a regex object is initialized with or assigned a new pattern. As with any programming language, it is possible that the regular expressions we write can have errors.
It is important to realize that the syntactic correctness of a regular expression is evaluated at run time.
If we make a mistake in writing a regular expression, then at run time the library will throw an exception (§ 5.6, p. 193) of type regex_error. Like the standard exception types, regex_error has a what operation that describes the error that occurred (§ 5.6.2, p. 195). A regex_error also has a member named code that returns a numeric code corresponding to the type of error that was encountered. The values code returns are implementation defined. The standard errors that the RE library can throw are listed in Table 17.7.
Table 17.7. Regular Expression Error Conditions

For example, we might inadvertently omit a bracket in a pattern:
try {
// error: missing close bracket after alnum; the constructor will throw
regex r("[[:alnum:]+\\.(cpp|cxx|cc)$", regex::icase);
} catch (regex_error e)
{ cout << e.what() << "\ncode: " << e.code() << endl; }
When run on our system, this program generates
regex_error(error_brack):
The expression contained mismatched [ and ].
code: 4
Our compiler defines the code member to return the position of the error as listed in Table 17.7, counting, as usual, from zero.
As we’ve seen, the “program” that a regular expression represents is compiled at run time, not at compile time. Compiling a regular expression can be a surprisingly slow operation, especially if you’re using the extended regular-expression grammar or are using complicated expressions. As a result, constructing a
regexobject and assigning a new regular expression to an existingregexcan be time-consuming. To minimize this overhead, you should try to avoid creating moreregexobjects than needed. In particular, if you use a regular expression in a loop, you should create it outside the loop rather than recompiling it on each iteration.
We can search any of several types of input sequence. The input can be ordinary char data or wchar_t data and those characters can be stored in a library string or in an array of char (or the wide character versions, wstring or array of wchar_t). The RE library defines separate types that correspond to these differing types of input sequences.
For example, the regex class holds regular expressions of type char. The library also defines a wregex class that holds type wchar_t and has all the same operations as regex. The only difference is that the initializers of a wregex must use wchar_t instead of char.
The match and iterator types (which we will cover in the following sections) are more specific. These types differ not only by the character type, but also by whether the sequence is in a library string or an array: smatch represents string input sequences; cmatch, character array sequences; wsmatch, wide string (wstring) input; and wcmatch, arrays of wide characters.
The important point is that the RE library types we use must match the type of the input sequence. Table 17.8 indicates which types correspond to which kinds of input sequences. For example:
regex r("[[:alnum:]]+\\.(cpp|cxx|cc)$", regex::icase);
smatch results; // will match a string input sequence, but not char*
if (regex_search("myfile.cc", results, r)) // error: char* input
cout << results.str() << endl;
Table 17.8. Regular Expression Library Classes

The (C++) compiler will reject this code because the type of the match argument and the type of the input sequence do not match. If we want to search a character array, then we must use a cmatch object:
cmatch results; // will match character array input sequences
if (regex_search("myfile.cc", results, r))
cout << results.str() << endl; // print the current match
In general, our programs will use string input sequences and the corresponding string versions of the RE library components.
Exercises Section 17.3.1
Exercise 17.14: Write several regular expressions designed to trigger various errors. Run your program to see what output your compiler generates for each error.
Exercise 17.15: Write a program using the pattern that finds words that violate the “i before e except after c” rule. Have your program prompt the user to supply a word and indicate whether the word is okay or not. Test your program with words that do and do not violate the rule.
Exercise 17.16: What would happen if your
regexobject in the previous program were initialized with"[^c]ei"?Test your program using that pattern to see whether your expectations were correct.
The program on page 729 that found violations of the “i before e except after c” grammar rule printed only the first match in its input sequence. We can get all the matches by using an sregex_iterator. The regex iterators are iterator adaptors (§ 9.6, p. 368) that are bound to an input sequence and a regex object. As described in Table 17.8 (on the previous page), there are specific regex iterator types that correspond to each of the different types of input sequences. The iterator operations are described in Table 17.9 (p. 736).
Table 17.9. sregex_iterator Operations

When we bind an sregex_iterator to a string and a regex object, the iterator is automatically positioned on the first match in the given string. That is, the sregex_iterator constructor calls regex_search on the given string and regex. When we dereference the iterator, we get an smatch object corresponding to the results from the most recent search. When we increment the iterator, it calls regex_search to find the next match in the input string.
sregex_iteratorAs an example, we’ll extend our program to find all the violations of the “i before e except after c” grammar rule in a file of text. We’ll assume that the string named file holds the entire contents of the input file that we want to search. This version of the program will use the same pattern as our original one, but will use a sregex_iterator to do the search:
// find the characters ei that follow a character other than c
string pattern("[^c]ei");
// we want the whole word in which our pattern appears
pattern = "[[:alpha:]]*" + pattern + "[[:alpha:]]*";
regex r(pattern, regex::icase); // we'll ignore case in doing the match
// it will repeatedly call regex_search to find all matches in file
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it)
cout << it->str() << endl; // matched word
The for loop iterates through each match to r inside file. The initializer in the for defines it and end_it. When we define it, the sregex_iterator constructor calls regex_search to position it on the first match in file. The empty sregex_iterator, end_it, acts as the off-the-end iterator. The increment in the for “advances” the iterator by calling regex_search. When we dereference the iterator, we get an smatch object representing the current match. We call the str member of the match to print the matching word.
We can think of this loop as jumping from match to match as illustrated in Figure 17.1.
Figure 17.1. Using an sregex_iterator
If we run this loop on test_str from our original program, the output would be
freind
theif
However, finding just the words that match our expression is not so useful. If we ran the program on a larger input sequence—for example, on the text of this chapter—we’d want to see the context within which the word occurs, such as
hey read or write according to the type
>>> being <<<
handled. The input operators ignore whi
In addition to letting us print the part of the input string that was matched, the match classes give us more detailed information about the match. The operations on these types are listed in Table 17.10 (p. 737) and Table 17.11 (p. 741).
Table 17.10. smatch Operations

Table 17.11. Submatch Operations

We’ll have more to say about the smatch and ssub_match types in the next section. For now, what we need to know is that these types let us see the context of a match. The match types have members named prefix and suffix, which return a ssub_match object representing the part of the input sequence ahead of and after the current match, respectively. A ssub_match object has members named str and length, which return the matched string and size of that string, respectively. We can use these operations to rewrite the loop of our grammar program:
// same for loop header as before
for (sregex_iterator it(file.begin(), file.end(), r), end_it;
it != end_it; ++it) {
auto pos = it->prefix().length(); // size of the prefix
pos = pos > 40 ? pos - 40 : 0; // we want up to 40 characters
cout << it->prefix().str().substr(pos) // last part of the prefix
<< "\n\t\t>>> " << it->str() << " <<<\n" // matched word
<< it->suffix().str().substr(0, 40) // first part of the suffix
<< endl;
}
The loop itself operates the same way as our previous program. What’s changed is the processing inside the for, which is illustrated in Figure 17.2.
Figure 17.2. The smatch Object Representing a Particular Match
We call prefix, which returns an ssub_match object that represents the part of file ahead of the current match. We call length on that ssub_match to find out how many characters are in the part of file ahead of the match. Next we adjust pos to be the index of the character 40 from the end of the prefix. If the prefix has fewer than 40 characters, we set pos to 0, which means we’ll print the entire prefix. We use substr (§ 9.5.1, p. 361) to print from the given position to the end of the prefix.
Having printed the characters that precede the match, we next print the match itself with some additional formatting so that the matched word will stand out in the output. After printing the matched portion, we print (up to) the first 40 characters in the part of file that comes after this match.
Exercises Section 17.3.2
Exercise 17.17: Update your program so that it finds all the words in an input sequence that violiate the “ei” grammar rule.
Exercise 17.18: Revise your program to ignore words that contain “ei” but are not misspellings, such as “albeit” and “neighbor.”
A pattern in a regular expression often contains one or more subexpressions. A subexpression is a part of the pattern that itself has meaning. Regular-expression grammars typically use parentheses to denote subexpressions.
As an example, the pattern that we used to match C++ files (§ 17.3.1, p. 730) used parentheses to group the possible file extensions. Whenever we group alternatives using parentheses, we are also declaring that those alternatives form a subexpression. We can rewrite that expression so that it gives us access to the file name, which is the part of the pattern that precedes the period, as follows:
// r has two subexpressions: the first is the part of the file name before the period
// the second is the file extension
regex r("([[:alnum:]]+)\\.(cpp|cxx|cc)$", regex::icase);
Our pattern now has two parenthesized subexpressions:
•
([[:alnum:]]+), which is a sequence of one or more characters
•
(cpp| cxx| cc), which is the file extension
We can also rewrite the program from § 17.3.1 (p. 730) to print just the file name by changing the output statement:
if (regex_search(filename, results, r))
cout << results.str(1) << endl; // print the first subexpression
As in our original program, we call regex_search to look for our pattern r in the string named filename, and we pass the smatch object results to hold the results of the match. If the call succeeds, then we print the results. However, in this program, we print str(1), which is the match for the first subexpression.
In addition to providing information about the overall match, the match objects provide access to each matched subexpression in the pattern. The submatches are accessed positionally. The first submatch, which is at position 0, represents the match for the entire pattern. Each subexpression appears in order thereafter. Hence, the file name, which is the first subexpression in our pattern, is at position 1, and the file extension is in position 2.
For example, if the file name is foo.cpp, then results.str(0) will hold foo.cpp; results.str(1) will be foo; and results.str(2) will be cpp. In this program, we want the part of the name before the period, which is the first subexpression, so we print results.str(1).
One common use for subexpressions is to validate data that must match a specific format. For example, U.S. phone numbers have ten digits, consisting of an area code and a seven-digit local number. The area code is often, but not always, enclosed in parentheses. The remaining seven digits can be separated by a dash, a dot, or a space; or not separated at all. We might want to allow data with any of these formats and reject numbers in other forms. We’ll do a two-step process: First, we’ll use a regular expression to find sequences that might be phone numbers and then we’ll call a function to complete the validation of the data.
Before we write our phone number pattern, we need to describe a few more aspects of the ECMAScript regular-expression language:
•
\{d}represents a single digit and\{d}{n}represents a sequence of n digits. (E.g.,\{d}{3}matches a sequence of three digits.)
• A collection of characters inside square brackets allows a match to any of those characters. (E.g.,
[-. ]matches a dash, a dot, or a space. Note that a dot has no special meaning inside brackets.)
• A component followed by ’?’ is optional. (E.g.,
\{d}{3}[-. ]?\{d}{4}matches three digits followed by an optional dash, period, or space, followed by four more digits. This pattern would match555-0132or555.0132or555 0132or5550132.)
• Like C++, ECMAScript uses a backslash to indicate that a character should represent itself, rather than its special meaning. Because our pattern includes parentheses, which are special characters in ECMAScript, we must represent the parentheses that are part of our pattern as
\(or\).
Because backslash is a special character in C++, each place that a \ appears in the pattern, we must use a second backslash to indicate to C++ that we want a backslash. Hence, we write \\{d}{3} to represent the regular expression \{d}{3}.
In order to validate our phone numbers, we’ll need access to the components of the pattern. For example, we’ll want to verify that if a number uses an opening parenthesis for the area code, it also uses a close parenthesis after the area code. That is, we’d like to reject a number such as (908.555.1800.
To get at the components of the match, we need to define our regular expression using subexpressions. Each subexpression is marked by a pair of parentheses:
// our overall expression has seven subexpressions: ( ddd ) separator ddd separator dddd
// subexpressions 1, 3, 4, and 6 are optional; 2, 5, and 7 hold the number
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})";
Because our pattern uses parentheses, and because we must escape backslashes, this pattern can be hard to read (and write!). The easiest way to read it is to pick off each (parenthesized) subexpression:
1.
(\\()?an optional open parenthesis for the area code
2.
(\\d{3})the area code
3.
(\\))?an optional close parenthesis for the area code
4.
([-. ])?an optional separator after the area code
5.
(\\d{3})the next three digits of the number
6.
([-. ])?another optional separator
7.
(\\d{4})the final four digits of the number
The following code uses this pattern to read a file and find data that match our overall phone pattern. It will call a function named valid to check whether the number has a valid format:
string phone =
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ]?)(\\d{4})";
regex r(phone); // a regex to find our pattern
smatch m;
string s;
// read each record from the input file
while (getline(cin, s)) {
// for each matching phone number
for (sregex_iterator it(s.begin(), s.end(), r), end_it;
it != end_it; ++it)
// check whether the number's formatting is valid
if (valid(*it))
cout << "valid: " << it->str() << endl;
else
cout << "not valid: " << it->str() << endl;
}
We’ll use submatch operations, which are outlined in Table 17.11, to write the valid function. It is important to keep in mind that our pattern has seven subexpressions. As a result, each smatch object will contain eight ssub_match elements. The element at [0]represents the overall match; the elements [1]. . .[7] represent each of the corresponding subexpressions.
When we call valid, we know that we have an overall match, but we do not know which of our optional subexpressions were part of that match. The matched member of the ssub_match corresponding to a particular subexpression is true if that subexpression is part of the overall match.
In a valid phone number, the area code is either fully parenthesized or not parenthesized at all. Therefore, the work valid does depends on whether the number starts with a parenthesis or not:
bool valid(const smatch& m)
{
// if there is an open parenthesis before the area code
if(m[1].matched)
// the area code must be followed by a close parenthesis
// and followed immediately by the rest of the number or a space
return m[3].matched
&& (m[4].matched == 0 || m[4].str() == " ");
else
// then there can't be a close after the area code
// the delimiters between the other two components must match
return !m[3].matched
&& m[4].str() == m[6].str();
}
We start by checking whether the first subexpression (i.e., the open parenthesis) matched. That subexpression is in m[1]. If it matched, then the number starts with an open parenthesis. In this case, the overall number is valid if the subexpression following the area code also matched (meaning that there was a close parenthesis after the area code). Moreover, if the number is correctly parenthesized, then the next character must be a space or the first digit in the next part of the number.
If m[1] didn’t match (i.e., there was no open parenthesis), the subexpression following the area code must also be empty. If it’s empty, then the number is valid if the remaining separators are equal and not otherwise.
Exercises Section 17.3.3
Exercise 17.19: Why is it okay to call
m[4].str()without first checking whetherm[4]was matched?Exercise 17.20: Write your own version of the program to validate phone numbers.
Exercise 17.21: Rewrite your phone number program from § 8.3.2 (p. 323) to use the
validfunction defined in this section.Exercise 17.22: Rewrite your phone program so that it allows any number of whitespace characters to separate the three parts of a phone number.
Exercise 17.23: Write a regular expression to find zip codes. A zip code can have five or nine digits. The first five digits can be separated from the remaining four by a dash.
regex_replaceRegular expressions are often used when we need not only to find a given sequence but also to replace that sequence with another one. For example, we might want to translate U.S. phone numbers into the form “ddd.ddd.dddd,” where the area code and next three digits are separated by a dot.
When we want to find and replace a regular expression in the input sequence, we call regex_replace. Like the search functions, regex_replace, which is described in Table 17.12, takes an input character sequence and a regex object. We must also pass a string that describes the output we want.
Table 17.12. Regular Expression Replace Operations

We compose a replacement string by including the characters we want, intermixed with subexpressions from the matched substring. In this case, we want to use the second, fifth, and seventh subexpressions in our replacement string. We’ll ignore the first, third, fourth, and sixth, because these were used in the original formatting of the number but are not part of our replacement format. We refer to a particular subexpression by using a $ symbol followed by the index number for a subexpression:
string fmt = "$2.$5.$7"; // reformat numbers to ddd.ddd.dddd
We can use our regular-expression pattern and the replacement string as follows:
regex r(phone); // a regex to find our pattern
string number = "(908) 555-1800";
cout << regex_replace(number, r, fmt) << endl;
The output from this program is
908.555.1800
A more interesting use of our regular-expression processing would be to replace phone numbers that are embedded in a larger file. For example, we might have a file of names and phone number that had data like this:
morgan (201) 555-2368 862-555-0123
drew (973)555.0130
lee (609) 555-0132 2015550175 800.555-0000
that we want to transform to data like this:
morgan 201.555.2368 862.555.0123
drew 973.555.0130
lee 609.555.0132 201.555.0175 800.555.0000
We can generate this transformation with the following program:
int main()
{
string phone =
"(\\()?(\\d{3})(\\))?([-. ])?(\\d{3})([-. ])?(\\d{4})";
regex r(phone); // a regex to find our pattern
smatch m;
string s;
string fmt = "$2.$5.$7"; // reformat numbers to ddd.ddd.dddd
// read each record from the input file
while (getline(cin, s))
cout << regex_replace(s, r, fmt) << endl;
return 0;
}
We read each record into s and hand that record to regex_replace. This function finds and transforms all the matches in its input sequence.
Just as the library defines flags to direct how to process a regular expression, the library also defines flags that we can use to control the match process or the formatting done during a replacement. These values are listed in Table 17.13 (overleaf). These flags can be passed to the regex_search or regex_match functions or to the format members of class smatch.

The match and format flags have type match_flag_type. These values are defined in a namespace named regex_constants. Like placeholders, which we used with bind (§ 10.3.4, p. 399), regex_constants is a namespace defined inside the std namespace. To use a name from regex_constants, we must qualify that name with the names of both namespaces:
using std::regex_constants::format_no_copy;
This declaration says that when our code uses format_no_copy, we want the object of that name from the namespace std::regex_constants. We can instead provide the alternative form of using that we will cover in § 18.2.2 (p. 792):
using namespace std::regex_constants;
By default, regex_replace outputs its entire input sequence. The parts that don’t match the regular expression are output without change; the parts that do match are formatted as indicated by the given format string. We can change this default behavior by specifying format_no_copy in the call to regex_replace:
// generate just the phone numbers: use a new format string
string fmt2 = "$2.$5.$7 "; // put space after the last number as a separator
// tell regex_replace to copy only the text that it replaces
cout << regex_replace(s, r, fmt2, format_no_copy) << endl;
Given the same input, this version of the program generates
201.555.2368 862.555.0123
973.555.0130
609.555.0132 201.555.0175 800.555.0000
Exercises Section 17.3.4
Exercise 17.24: Write your own version of the program to reformat phone numbers.
Exercise 17.25: Rewrite your phone program so that it writes only the first phone number for each person.
Exercise 17.26: Rewrite your phone program so that it writes only the second and subsequent phone numbers for people with more than one phone number.
Exercise 17.27: Write a program that reformats a nine-digit zip code as
ddddd-dddd.

 Tip
Tip Note
Note
